K-Means聚类算法实现签到IP的自动聚类与知识主题的抽取
适用系统:Ubuntu, Centos, Debain, Deepin, Mac OS, Windows, Raspberry Pi
开发环境: Deepin 15.5
开发语言: Python3.6.4
开发工具: Pycharm
作者: Mr.Li
K-Means概念
- 聚类(Clustering):K-Means 是一种聚类分析(Cluster Analysis)方法。聚类就是将数据对象分组成为多个类或者簇 (Cluster),使得在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。
- 划分(Partitioning):聚类可以基于划分,也可以基于分层。划分即将对象划分成不同的簇,而分层是将对象分等级。
- 排他(Exclusive):对于一个数据对象,只能被划分到一个簇中。如果一个数据对象可以被划分到多个簇中,则称为可重叠的(Overlapping)。
- 距离(Distance):基于距离的聚类是将距离近的相似的对象聚在一起。基于概率分布模型的聚类是在一组对象中,找到能符合特定分布模型的对象的集合,他们不一定是距离最近的或者最相似的,而是能完美的呈现出概率分布模型所描述的模型。
K-Means算法的实现
- 由于 K-Means 算法值针对给定的完整数据集进行操作,不需要任何特殊的训练数据,所以 K-Means 是一种无监督的机器学习方法(Unsupervised Machine Learning Technique)。
-
KMeans算法试图使集群数据分为n组独立数据样本,使n组集群间的方差相等,数学描述为最小化惯性或集群内的平方和。该算法的缺点在于需要提前确定数据集群的类别n,虽然有些预处理算法可以确定n的取值,但是会增加很大一部分的计算复杂度。规模适合大量的样品,被使用在在许多不同的领域。
- 在介绍 k-means 的具体步骤之前,让我们先来看看它对于需要进行聚类的数据的一个基本假设吧:对于每一个 cluster ,我们可以选出一个中心点(center),使得该cluster中的所有的点到该中心点的距离小于到其他 cluster 的中心的距离。虽然实际情况中得到的数据并不能保证总是满足这样的约束,但这通常已经是我们所能达到的最好的结果,而那些误差通常是固有存在的或者问题本身的不可分性造成的。例如下图所示的两个高斯分布,从两个分布中随机地抽取一些数据点出来,混杂到一起,现在要让你将这些混杂在一起的数据点按照它们被生成的那个分布分开来:
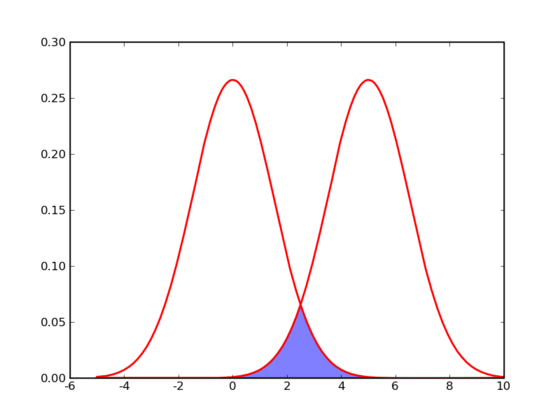
- 由于这两个分布本身有很大一部分重叠在一起了,例如,对于数据点2.5来说,它由两个分布产生的概率都是相等的,你所做的只能是一个猜测;稍微好一点的情况是2,通常我们会将它归类为左边的那个分布,因为概率大一些,然而此时它由右边的分布生成的概率仍然是比较大的,我们仍然有不小的几率会猜错。而整个阴影部分是我们所能达到的最小的猜错的概率,这来自于问题本身的不可分性,无法避免。因此,我们将 k-means 所依赖的这个假设看作是合理的。
数学建模
- k-means算法将n组样本划分为不相交的集群Ck每个集群中用样本的均值μk所描述的。这些均值通常称为集群“重心”(加权即为重心,不加权就是中心)。请注意,一般来说,他们不是每个集群Ck中的点,尽管重心和Ck中的点在同一个空间。k - means算法旨在选择重心,减少惯性,或集群内平方和的准则:
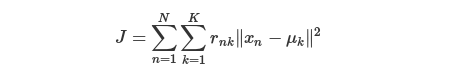
-
这个函数,其中rnk在数据点 n被归类到 clusterk的时候为 1 ,否则为 0 。直接寻找 rnk 和μk来最小化 J 并不容易,不过我们可以采取迭代的办法:先固定 μk ,选择最优的rnk ,很容易看出,只要将数据点归类到离他最近的那个中心就能保证 J 最小。下一步则固定rnk,再求最优的 μk。将J 对μk 求导并令导数等于零,很容易得到 J最小的时候 μk
-
应该满足:
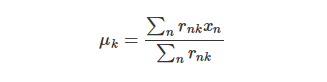
-
亦即 μk的值应当是所有 cluster k 中的数据点的平均值。由于每一次迭代都是取到 J 的最小值,因此 J 只会不断地减小(或者不变),而不会增加,这保证了 k-means 最终会到达一个极小值。虽然 k-means 并不能保证总是能得到全局最优解,但是对于这样的问题,像 k-means 这种复杂度的算法,这样的结果已经是很不错的了。
- 惯性或集群内平方和准则,可以被视为衡量内部是如何耦合的标准。它存在各种各样的缺点:
- 惯性必须假设集群数据是凸和各向同性的,然而数据并非总是能保持这个特性。细长的集群,或不规则形状将响应差。
- 惯性不是一个标准化的指标:我们只知道更低的值是更好的和零是最优的。但在高维空间,欧几里得距离往往会变得膨胀(这是所谓的“维数的诅咒”的一个实例)。在使用k-means聚类之前运用如PCA降维可以缓解这个问题,加速计算。
- k-means是基于欧几里得距离公式来计算的,所以它是适用于任何高维空间的,当然这个思想其实可以扩展到任意可以用来评价相似性的基础公式,如切比雪夫距离和相关性公式等。
———-概念讲完直接上代码———-
推导选择最佳簇集
作为屌丝界的程序员,经常敲代码,字丑将就着看吧

簇的最小化SSE的最佳质心是簇中各点的均值
签到数据进行聚类分析的实现
接下来主要讲解如何使用K-Means算法对签到数据进行聚类分析,从而可以从中查找到异常的IP值
* 1 爬取数据,本篇文章所使用的数据是从公司内网爬取的,共14316条数据
* 2 对数据进行TF-IDF加权处理
* 3 创建聚类器
* 4 设置参数并对数据进行训练
* 5 保存模型返回分类索引
* 6 拼接原始数据
* 7 为数据添加分类标签并导出数据
头文件
import os
import csv
import time
import random
import pandas as pd
from lxml import etree
from http import cookiejar
from urllib import request
from urllib.parse import urlencode
from sklearn.cluster import KMeans
from sklearn.externals import joblib
from sklearn.feature_extraction.text import TfidfVectorizer
爬取签到信息
创建数据爬取类并进行初始化
class SpiderSign(object):
# 初始化
def __init__(self, filename=None):
if not filename: raise Exception('请输入要保存的文件路径及文件名')
# 创建csv实例化对象
csv_file = open(filename, 'a', newline='')
self.csv_wirter = csv.writer(csv_file)
self.csv_wirter.writerow(['姓名', '签到时间', 'IP', '状态', '去向'])
# cookie
self.mycookies = None
获取Cookie
def login_cookies(self):
url = 'http://www.******.action'
# 登陆账号
datas = {'***': '***',
'***': ***}
# 对登陆账号进行编码
datas = urlencode(datas).encode()
# 创建cookiejar
mycookiejar = cookiejar.CookieJar()
# 创建cookiejar处理器
handlers = request.HTTPCookieProcessor(mycookiejar)
# 创建opener并加入请求头
opener = request.build_opener(handlers)
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36')]
# 获取cookie
myrequest = request.Request(url=url,
data=datas)
# 登陆结果
datas = opener.open(myrequest)
# 拼接cookie
cookie_str = ''
for strs in mycookiejar:
cookie_str = strs.name + '=' + strs.value
print('获取Cookie:{}'.format(cookie_str))
print('登陆结果:', datas.read().decode())
return cookie_str
获取总页数
def total_page(self, pagesize):
# 读取前100页数据
datas = self.curent_html(1, pagesize)
# 转换为HTML格式
html = etree.HTML(datas)
# 使用xpath定位标签信息
total_pages = html.xpath('.//div[@class="fyh"]/ul/a[last()-1]/text()')[0]
print('获得总页数{}(sizePage={}):'.format(total_pages, pagesize))
return int(total_pages)+1
获取当前页内容
def curent_html(self, pageNum, pageSize):
url = 'http://www.******.action'
# 请求参数 pangenum
parmaters = {'pageNum':pageNum,
'pageSize':pageSize,
'queryType':1}
# 对请求参数进行编码
parmaters = urlencode(parmaters).encode()
# 创建Request请求
req = request.Request(url)
req.add_header('Cookie', self.mycookies)
req.add_header('User-Agent', 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36')
# 获取请求结果
result = request.urlopen(req, data=parmaters)
# 对返回内容解码并过滤无用转义符
return result.read().decode().replace('\t','').replace('\n','').replace('\r','')
使用Xpath过滤签到信息并保存到.csv文件中
def __filter_xpath(self, pageNum=1, pageSize=100):
# 转换为HTML格式
html = etree.HTML(self.curent_html(pageNum, pageSize))
user_info = html.xpath('.//tr[position()>1]')
# 过滤内容
for infos in user_info:
info_list = []
# 使用xpath获取标签信息
name = infos.xpath('./td[@class="namecomm"]/text()')
time = infos.xpath('./td[position()=3]/text()')
ip = infos.xpath('./td[position()=4]/text()')
status = infos.xpath('./td[last()-3]/text()')
derection = infos.xpath('./td[last()-2]/text()')
if name:
info_list.append(name[0].strip())
info_list.append(time[0])
info_list.append(ip[0])
info_list.append(status[0].strip())
info_list.append(derection[0])
# 将数据保存到文件中
self.csv_wirter.writerow(info_list)
# 记录数据条数
self.rowNum += 1
print('写入数据:{}'.format('|'.join(info_list)))
print('----------------第{}页爬取完成--------------------'.format(pageNum))
开始爬取数据
def spider_sign_run(self, pagesize):
# 获取cookie信息
self.mycookies = self.login_cookies()
thd_list = []
# 为每页开启一个子线程并开始爬取数据
for page in range(1, self.total_page(pagesize)):
try:
# 开辟子线程
ip_thd = Thread(target=self.__filter_xpath, args=(page, pagesize))
ip_thd.start()
except Exception as error:
print('线程开启失败:',error)
else:
thd_list.append(ip_thd)
# 阻塞等待, 等待所有的子线程运行结束并回收
for thd_end in thd_list:
thd_end.join()
print('\n数据爬取完成,共爬取{}条数据,耗时:{},开始对数据进行聚类训练...\n'.format(self.rowNum,
time.time()-self.startTime))
运行结果:
登陆结果: 2
获得总页数144(sizePage=100):
写入数据:***|2018-05-11 09:25|39.155.158.229|迟到|zdt
写入数据:***|2018-05-11 09:09|39.155.158.229|迟到|zdt
写入数据:***|2018-05-11 09:07|106.38.121.53|迟到|zdt
写入数据:***|2018-05-11 09:01|106.38.121.53|迟到|zdt
写入数据:***|2018-05-11 08:59|39.155.158.229|正常|zdt
写入数据:***|2018-05-11 08:59|106.38.121.53|正常|zdt
写入数据:***|2018-05-11 08:58|223.72.76.144|正常|gs
写入数据:***|2018-05-11 08:55|106.38.121.53|正常|zdt
写入数据:***|2018-05-11 08:54|106.38.121.53|正常|zdt
...... ....... ......
----------------第136页爬取完成--------------------
...... ....... ......
写入数据:***|2016-01-05 08:26|123.120.23.46|正常|公司
写入数据:***|2016-01-04 10:31|123.120.23.46|迟到|gs
写入数据:***|2016-01-04 09:01|211.99.16.14|迟到|zdt
写入数据:***|2016-01-04 08:59|123.120.23.46|正常|gs
写入数据:***|2016-01-04 08:59|106.120.141.182|正常|zdt
写入数据:***|2016-01-04 08:58|211.99.16.14|正常|zdt
写入数据:***|2016-01-04 08:57|211.99.16.14|正常|zdt
写入数据:***|2016-01-04 08:56|123.120.23.46|正常|公司
----------------第143页爬取完成--------------------
..... ....... ......
数据爬取完成,共爬取14316条数据,耗时:16.204238176345825,开始对数据进行聚类训练...
正在对数据进行加权与聚类处理...
IP数据的聚类
创建类并进行初始化
class SignKmeans(object):
# 初始化
def __init__(self, filename=None, n_cluster=5):
if not filename: raise Exception('请输入文件名')
self.sign_data = pd.read_csv(filename)
self.n_cluster = n_cluster
n_cluser为聚类器的聚类数量
TF-IDF数据加权处理
def __tfidf_deal(self):
print('正在对数据进行加权与聚类处理...')
sign_datas = self.sign_data['IP']
tfidf = TfidfVectorizer()
tfidf_datas = tfidf.fit_transform(sign_datas)
print(tfidf.get_feature_names())
print(tfidf_datas.toarray())
return tfidf_datas
运行结果:
[[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
...
[0. 0. 0. ... 0. 0. 0.50323076]
[0. 0. 0. ... 0. 0. 0.50323076]
[0. 0. 0. ... 0. 0. 0. ]]
使用K-Means算法对数据进行聚类
def kmeans_cluster(self):
# 创建聚类器
n_cluster = 5
km = KMeans(n_clusters=n_cluster,
max_iter=300,
n_init=50,
init='k-means++',
n_jobs=30)
km.fit(self.__tfidf_deal())
# 对数据进行聚类的索引结果为
kmlabels = km.labels_.tolist()
print('聚类完成')
# 保存模型
joblib.dump(km, '../Datas/Models/Signmodel.pkl')
print('模型保存成功')
return kmlabels
n_clusters 聚类数量, max_iter 最大迭代次数, n_init 重新选择初始值的次数, init 制定初始值选择算法, n_jobs 最大进程数,为-1时CPU満载运行
运行结果:
[1 1 3 ... 2 2 2]
根据聚类索引对数据进行聚类划分
def mark_datas(self):
sign_label = ['姓名', '签到时间', 'IP', '状态', '去向']
sign_all_data = [self.sign_data[label].tolist() for label in sign_label]
# 拼接数据
tmpout = []
for i in range(len(sign_all_data[0])):
tmpin = []
for signs in sign_all_data:
tmpin.append(signs[i])
tmpout.append(tmpin)
# 将数据导出
data = pd.DataFrame(tmpout,
index=[self.kmeans_cluster()],
columns=sign_label)
data.to_excel(pd.ExcelWriter('../Datas/SignClass.xlsx'), sheet_name='聚类数据')
print(data)
运行结果:
聚类类别 签到时间 IP 状态 去向
1 2018/5/10 11:19 39.155.158.229 迟到 杂志社
1 2018/5/10 9:22 39.155.158.229 迟到 zdt
2 2018/5/10 9:20 106.38.121.53 迟到 zdt
2 2018/5/10 9:18 106.38.121.53 迟到 zdt
2 2018/5/10 9:00 106.38.121.53 迟到 zdt
1 2018/5/10 8:59 39.155.158.229 正常 zdt
2 2018/5/10 8:58 106.38.121.53 正常 zdt
2 2018/5/10 8:58 106.38.121.53 正常 zdt
2 2018/5/10 8:58 106.38.121.53 正常 zdt
1 2018/5/10 8:57 39.155.158.229 正常 zdt
1 2018/5/10 8:57 39.155.158.229 正常 zdt
0 2018/5/10 8:57 223.72.76.144 正常 gs
0 2018/5/10 8:57 223.72.76.144 正常 gs
.. ... ... ... ...
3 2016/1/5 8:44 106.120.141.182 正常 zdt
3 2016/1/5 8:43 123.120.23.46 正常 gs
3 2016/1/5 8:42 106.120.141.181 正常 zdt
4 2016/1/5 8:37 211.99.16.14 正常 zdt
3 2016/1/5 8:34 123.120.23.46 正常 gs
3 2016/1/4 8:43 123.120.23.46 正常 gs
3 2016/1/4 8:39 123.120.23.46 正常 gs
3 2016/1/4 8:36 123.120.23.46 正常 gs
3 2016/1/4 8:29 123.120.23.46 正常 gs
3 2016/1/3 14:07 123.120.23.46 迟到 gs
3 2016/1/3 14:07 123.120.23.46 迟到 gs
3 2016/1/3 14:04 123.120.23.46 迟到 gs
从运行结果来看,IP数据被整体聚成了5大类,以下是选择类别0与类别3时的效果
类别 签到时间 IP 状态 去向
0 2018-05-11 09:25 39.155.158.229 迟到 zdt
0 2018-05-11 09:09 39.155.158.229 迟到 zdt
0 2018-05-11 08:59 39.155.158.229 正常 zdt
0 2018-05-11 08:53 39.155.158.229 正常 zdt
0 2018-05-11 08:52 39.155.158.229 正常 zdt
0 2018-05-11 08:49 39.155.158.229 正常 zdt
0 2018-05-11 08:44 39.155.158.229 正常 zdt
0 2018-05-11 08:38 39.155.158.229 正常 zdt
0 2018-05-11 08:37 39.155.158.229 正常 zdt
0 2018-05-11 08:00 39.155.158.229 正常 zdt
0 2018-05-10 11:19 39.155.158.229 迟到 杂志社
0 2018-05-10 09:22 39.155.158.229 迟到 zdt
.. ... ... ... ...
3 2018-05-11 08:58 223.72.76.144 正常 gs
3 2018-05-11 08:50 223.72.76.144 正常 gs
3 2018-05-11 08:50 223.72.76.144 正常 gs
3 2018-05-11 08:49 223.72.76.144 正常 gs
3 2018-05-11 08:46 223.72.76.144 正常 gs
3 2018-05-11 08:46 223.72.76.144 正常 gs
3 2018-05-09 08:54 117.136.38.56 正常 zdt
.. ... ... ... ...
文章的聚类与主题抽取
文章的聚类
同理也可以对论文,期刊,新闻等进行聚类,以下是对364篇医学论文根据文章内容进行的聚类,这里同样聚成5类,效果如下:
类别 文章标题
4 _祛痰化瘀汤_治疗支气管哮喘25例临床观察_闫炳远.txt
2 三三九咳散治疗咳嗽变异性哮喘51例临床研究.txt
3 三才消哮饮治疗小儿哮喘缓解期临床研究_何富乐.txt
4 三拗汤合三子养亲汤加减治疗过敏性哮喘急性期的临床观察.txt
4 两种不同方法治疗成人哮喘的疗效观察.txt
4 两种治疗方案对儿童哮喘急性发作的疗效评价.txt
2 中医分期辨治对咳嗽变异性哮喘患儿血清IgE及ECP的影响.txt
4 中医综合治疗支气管哮喘40例.txt
2 中医药治疗咳嗽变异性哮喘随机对照试验的系统评价.txt
4 中医药治疗小儿哮喘缓解期临床观察.txt
3 中医药治疗急性发作期支气管哮喘的系统评价_李建生.txt
3 中医药治疗支气管哮喘缓解期的系统评价_李建生.txt
4 中医药辅助治疗职业性哮喘的疗效观察.txt
3 中医辨证施护对小儿哮喘患者生存质量的影响_刘苗芳.txt
4 中药加新鲜胎盘治疗支气管哮喘69例的疗效观察.txt
1 中药止咳平喘方对支原体诱发哮喘患儿Th亚群和IgE的影响_柴伟.txt
4 补肺益肾中药方对支气管哮喘缓解期患者肺功能的影响_孙彦.txt
3 补肺益肾膏治疗支气管哮喘非急性发作期的临床疗效观察.txt
0 补肺益肾膏治疗支气管哮喘非急性发作期的临床疗效观察_徐则林.txt
3 补肺颗粒对哮喘缓解期患者生活质量的影响_陈艳华.txt
4 补肺颗粒治疗哮喘缓解期疗效观察.txt
3 补肺颗粒治疗哮喘缓解期疗效观察_李小娟.txt
2 补肾宣肺方治疗肾阳虚咳嗽变异性哮喘临床研究.txt
.. ... ... ... ...
选择其中两个类别,其聚类效果如下:
类别 文章标题
0 补肺益肾膏治疗支气管哮喘非急性发作期的临床疗效观察_徐则林.txt
0 辛苍汤鼻腔灌洗对哮喘儿童缓解期细胞因子的调控作用.txt
0 支气管哮喘儿童气质特征分析及临床干预研究.txt
0 支气管哮喘合并侵袭性肺曲霉菌病1例报告.txt
0 支气管哮喘合并变应性鼻炎上下气道共治的临床观察.txt
0 支气管哮喘合并曲霉菌感染1例.txt
0 支气管哮喘合并烟曲霉菌感染1例.txt
0 支气管哮喘合并甲状腺肿大致呼吸困难1例.txt
0 支气管哮喘患儿呼出气一氧化氮变化的临床观察_吴绍霞.txt
0 支气管哮喘患儿血Th17细胞变化及槐杞黄颗粒的干预作用.txt
0 支气管哮喘患者外周血嗜酸粒细胞上前列腺素D2受体改变研究.txt
0 固本止喘膏防治支气管哮喘临床观察_蒲春阳.txt
0 固肺镇咳中药及其拆方对支气管哮喘_省略_Th17_Treg平衡的调节作用_蒲伟.txt
0 培土生金法防治儿童哮喘46例.txt
0 加味参附姜苓汤对围月经期咳嗽变异性哮喘患者血清MMP2、MMP9及TIMP1表达的影响.txt
0 红花注射液过敏引起急性哮喘发作1例_于峰.txt
0 过敏性哮喘屋尘螨变应原集群免疫治疗与常规免疫治疗的对照研究.txt
0 过敏性支气管肺真菌病误诊为哮喘1例.txt
.. ... ... ... ...
类别 文章标题
2 三三九咳散治疗咳嗽变异性哮喘51例临床研究.txt
2 中医分期辨治对咳嗽变异性哮喘患儿血清IgE及ECP的影响.txt
2 中医药治疗咳嗽变异性哮喘随机对照试验的系统评价.txt
2 补肾宣肺方治疗肾阳虚咳嗽变异性哮喘临床研究.txt
2 调气解痉祛痰法治疗儿童咳嗽变异性哮喘30例.txt
2 平肝清肺颗粒加减治疗小儿咳嗽变异性哮喘的临床研究_劳慧敏.txt
2 抗支口服液治疗咳嗽变异性哮喘疗效观察.txt
2 定喘止咳汤治疗儿童咳嗽变异性哮喘_省略_对患者血清总IgE和EOS的影响_符卫民.txt
2 敏咳口服液治疗咳嗽变异性哮喘的临床研究_梁建卫.txt
2 苏黄止咳胶囊对咳嗽变异性哮喘患者血嗜酸性粒细胞和呼出气一氧化氮的影响.txt
2 过敏煎加味治疗咳嗽变异性哮喘64例临床观察.txt
2 运用异病同治法治疗SCOPD和支气管哮喘慢性持续期患者的疗效评价.txt
2 运用异病同治法论治慢性阻塞性肺疾病稳定期和哮喘持续期临床疗效分析.txt
2 金匮肾气丸合参蛤散治疗小儿肾不纳气型哮喘疗效观察.txt
2 咳喘一号配合平喘膏治疗咳嗽变异性哮喘56例.txt
2 咳喘清口服液治疗小儿哮喘热喘58例临床观察.txt
从聚类结果来看,训练出来的聚类模型将论文划分成了不同属性的类别,因为本人并非医学出身所以并不能明确的区分出这两类文章是否真的属于不同的类别.那么如何解决像我这种医学小白的尴尬呢?
主题的抽取
我们采用LDA主题模型对文章进行主题的抽取,然后我们就可以根据文章的主题词快速的分辨出来文章的中心思想,所属类别以及文章与文章之间的关系了,想想有没有觉得有点小激动……先忍着,接下来先看点有关LDA的概念,概念有点罗嗦,不想看可以直接跳过看结果
概念
-
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
-
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布
LDA生成过程
- 对于语料库中的每篇文档,LDA定义了如下生成过程(generativeprocess):
- 1.对每一篇文档,从主题分布中抽取一个主题;
- 2.从上述被抽到的主题所对应的单词分布中抽取一个单词;
- 3.重复上述过程直至遍历文档中的每一个单词。
- 语料库中的每一篇文档与T(通过反复试验等方法事先给定)个主题的一个多项分布 (multinomialdistribution)相对应,将该多项分布记为θ。每个主题又与词汇表(vocabulary)中的V个单词的一个多项分布相对应,将这个多项分布记为φ
LDA整体流程
- 先定义一些字母的含义:文档集合D,主题(topic)集合T
- D中每个文档d看作一个单词序列<w1,w2,…,wn>,wi表示第i个单词,设d有n个单词。(LDA里面称之为wordbag,实际上每个单词的出现位置对LDA算法无影响)
- D中涉及的所有不同单词组成一个大集合VOCABULARY(简称VOC),LDA以文档集合D作为输入,希望训练出的两个结果向量(设聚成k个topic,VOC中共包含m个词):
- 对每个D中的文档d,对应到不同Topic的概率θd<pt1,…,ptk>,其中,pti表示d对应T中第i个topic的概率。计算方法是直观的,pti=nti/n,其中nti表示d中对应第i个topic的词的数目,n是d中所有词的总数。
- 对每个T中的topict,生成不同单词的概率φt<pw1,…,pwm>,其中,pwi表示t生成VOC中第i个单词的概率。计算方法同样很直观,pwi=Nwi/N,其中Nwi表示对应到topict的VOC中第i个单词的数目,N表示所有对应到topict的单词总数。
- LDA的核心公式如下: p(w|d)=p(w|t)*p(t|d)
-
直观的看这个公式,就是以Topic作为中间层,可以通过当前的θd和φt给出了文档d中出现单词w的概率。其中p(t d)利用θd计算得到,p(w t)利用φt计算得到。 -
实际上,利用当前的θd和φt,我们可以为一个文档中的一个单词计算它对应任意一个Topic时的p(w d),然后根据这些结果来更新这个词应该对应的topic。然后,如果这个更新改变了这个单词所对应的Topic,就会反过来影响θd和φt。
LDA学习过程
- LDA算法开始时,先随机地给θd和φt赋值(对所有的d和t)。然后上述过程不断重复,最终收敛到的结果就是LDA的输出。再详细说一下这个迭代的学习过程:
- 1.针对一个特定的文档ds中的第i单词wi,如果令该单词对应的topic为tj,可* 以把上述公式改写为:
-
pj(wi ds)=p(wi tj)*p(tj ds) -
2.现在我们可以枚举T中的topic,得到所有的pj(wi ds),其中j取值1~k。然后可以根据这些概率值结果为ds中的第i个单词wi选择一个topic。最简单的想法是取令pj(wi ds)最大的tj(注意,这个式子里只有j是变量),即argmax[j]pj(wi ds) -
3.然后,如果ds中的第i个单词wi在这里选择了一个与原先不同的topic,就会对θd和φt有影响了(根据前面提到过的这两个向量的计算公式可以很容易知道)。它们的影响又会反过来影响对上面提到的p(w d)的计算。对D中所有的d中的所有w进行一次p(w d)的计算并重新选择topic看作一次迭代。这样进行n次循环迭代之后,就会收敛到LDA所需要的结果了。
———-概念讲完(概念不懂可以百度)———-
鉴于Demo尚有不足且代码量较大,此处不再展示代码…………不显示点代码总觉得良心在受到谴责,好吧就显示点头文件吧
import os
import re
import lda
import jieba
import numpy as np
import lda.datasets
import matplotlib.pyplot as plt
from sklearn.externals import joblib
from Customer.CustomError import Error
from Modules.AKArticle_Read import TxtRead
from Modules.AKArticle_CountVectorizer import ArticleCount
from sklearn.feature_extraction.text import CountVectorizer
... ... ... ...
从364篇论文中抽取10个主题, 主题词如下所示:
Topic 0 : 夜交藤 加服 不治痰 郁证 obstruction ially 阚佑 病历 aarsland
Topic 1 : 孢噻 通腑安 verleden 陈济 相异 巴中市 对支 听后 magnesium 荥阳
Topic 2 : 法等 赖克方 医保 苟超 均明 为昼 英才 益智仁 两虚用
Topic 3 : 钟礼立 即常 史和免 以淫 巡视 哮稼 梧州 中叶 胡玲
Topic 4 : 骤然 搜集 夜交藤 香气 煎治 张素 高血 加服
Topic 5 : 夜交藤 高及 ially 削弱 孢噻 娇 productionandactivitiesoftnf 郁证 cuvello
Topic 6 : 孢噻 仪分 经济负担 ially 郁证 各吸 多层次 相异 aarsland 削弱
Topic 7 : 孢噻 夜交藤 经济负担 相异 筛查 稳定性 多层次 spss
Topic 8 : 首重 子酸收 小肠 喘鸣 孢噻 稳定性 仪分 气压 ially
Topic 9 : 百分 江载芳 阴津 低于 海晶天 夏秋 同意权 哮稼
每篇文章中可以抽取到的最大主题词个数为:
_祛痰化瘀汤_治疗支气管哮喘25例临床观察_闫炳远 (Top 主题: 6)
三三九咳散治疗咳嗽变异性哮喘51例临床研究 (Top 主题: 6)
三才消哮饮治疗小儿哮喘缓解期临床研究_何富乐 (Top 主题: 7)
三拗汤合三子养亲汤加减治疗过敏性哮喘急性期的临床观察 (Top 主题: 6)
两种不同方法治疗成人哮喘的疗效观察 (Top 主题: 7)
两种治疗方案对儿童哮喘急性发作的疗效评价 (Top 主题: 7)
中医分期辨治对咳嗽变异性哮喘患儿血清IgE及ECP的影响 (Top 主题: 7)
中医综合治疗支气管哮喘40例 (Top 主题: 6)
中医药治疗咳嗽变异性哮喘随机对照试验的系统评价 (Top 主题: 0)
中医药治疗小儿哮喘缓解期临床观察 (Top 主题: 7)
中医药治疗急性发作期支气管哮喘的系统评价_李建生 (Top 主题: 0)
中医药治疗支气管哮喘缓解期的系统评价_李建生 (Top 主题: 0)
中医药辅助治疗职业性哮喘的疗效观察 (Top 主题: 7)
中医辨证施护对小儿哮喘患者生存质量的影响_刘苗芳 (Top 主题: 2)
中药加新鲜胎盘治疗支气管哮喘69例的疗效观察 (Top 主题: 7)
中药止咳平喘方对支原体诱发哮喘患儿Th亚群和IgE的影响_柴伟 (Top 主题: 4)
... ... ... ... ...
为了便于理解我在网上下载了一篇3千多字的文章,文章题目是 “科技改变生活”,将文章内容通过创建的LDA模型进行主题词的抽取,看一下与我们人为阅读文章时总结的主题是否相似,我们先来抽一个主题并让其包含7个主题词,效果如下:
文章主题1 : 科技 我们 生活 改变 人类 发展 人们
由此可以看出,抽取一个主题时,与我们人为阅读文章总结的主题已经很接近了
对文章抽取3个主题,每个主题包含5个主题词,效果如下:
文章主题1 : 我们 生活 人类 发展 带来
文章主题2 : 科技 改变 没有 高科技 变化
文章主题3 : 人们 能够 什么 以前 如果
对一篇文章抽取多个主题时,主题思想不是很明确,但是主题词较为丰富.
那么有没有办法,我们提供主题词,让训练好的模型根据主题词自动生成文章呢?只能说小伙子很有想法,答案是肯定的,等下次再写文章时,就会根据主题词自动生成文章内容